Analyzing the Impact of
Activity, Lying and Ruminating Features
for Accurate Calving Prediction
Introduction

This study aims to assess prepartum behavior and predict calving in Indian cattle using automated monitors for activity, lying, and rumination. Th dataset we used was collected from a group of Holstein dairy cattle at the University of Kentucky Coldstream Dairy. The study utilized HR Tags and IceQube devices to automatically gather data on neck activity, rumination, number of steps, lying time, standing time, transitions between standing and lying, and total motion. Examining feature selection methods (Filter Method, Wrapper Method, Embedded Method), we scrutinized and identified valuable features given the constraint of restricted cattle movement in Indian dairy scenarios. Later, we customized machine learning models intended for deployment on sensing devices, with the future application in agricultural farms.
Methodology
The research initiation involved a thorough examination of the existing dataset, pinpointing constraints related to physical movement, grazing, diverse management approaches, feeding practices, local climate patterns, resource limitations, and behavioral aspects of Indian cattle. This understanding was enriched through direct interactions with local farmers, shedding light on the nuanced conditions of Indian cattle. Additionally, we delved into pertinent literature to gather insights into the nature of Indian cattle activity. Consequently, the study emphasizes the imperative of employing innovative techniques like filter methods, wrapper methods, and embedded methods. These strategies are deemed crucial for distilling key features from a vast array of variables, a pivotal step in crafting more accurate and robust prediction models.
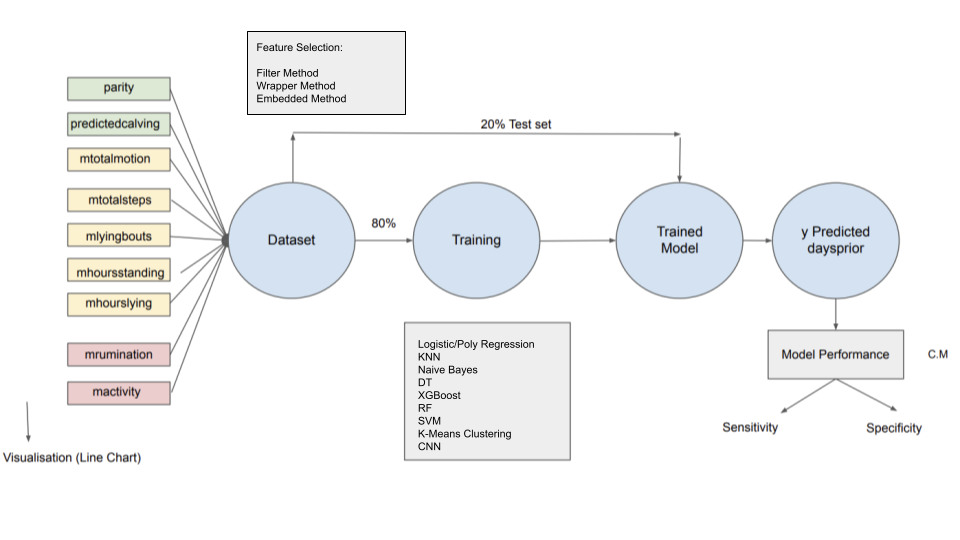

Below is the sample code of the feature selection methods adopted on a demo dataset:
import pandas as pd
import numpy as np
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
# ------------------------------------- Filter Method -----------------------------------------------------
# Load your dataset into a pandas DataFrame
df = pd.read_csv('hour.csv')
# Separate the features (X) and target variable (y)
y = df['hoursbefore']
X = df[["parity", "TIME", "avgtotalmotion", "avgtotalsteps", "avglyingbouts", "avgrumination", "avgactivity", "avghoursstanding", "avghourslying"]]
# Identify numeric and categorical columns
numeric_cols = X.select_dtypes(include=np.number).columns
categorical_cols = X.select_dtypes(include='object').columns
# Create transformers for numeric and categorical columns
numeric_transformer = SimpleImputer(strategy='mean')
categorical_transformer = SimpleImputer(strategy='most_frequent')
# Apply transformers to the columns
preprocessor = ColumnTransformer(
transformers=[
('numeric', numeric_transformer, numeric_cols),
('categorical', categorical_transformer, categorical_cols)
])
# Fit and transform the data
X_preprocessed = preprocessor.fit_transform(X)
# Convert back to DataFrame
X_preprocessed = pd.DataFrame(X_preprocessed, columns=numeric_cols.tolist() + categorical_cols.tolist())
# Perform one-hot encoding
encoder = OneHotEncoder(drop='first')
X_encoded = encoder.fit_transform(X_preprocessed[categorical_cols])
X_encoded = pd.DataFrame(X_encoded.toarray(), columns=encoder.get_feature_names_out(categorical_cols))
# Concatenate encoded features with numeric features
X_final = pd.concat([X_preprocessed[numeric_cols], X_encoded], axis=1)
# Initialize SelectKBest with f_classif scoring function
k = 5 # Number of top features to select
selector = SelectKBest(score_func=f_classif, k=k)
# Fit the selector to the data and transform the features
X_new = selector.fit_transform(X_final, y)
# Get the selected feature indices
feature_indices = selector.get_support(indices=True)
# Get the selected feature names
selected_features = X_final.columns[feature_indices]
# Print the selected feature names
print("Selected Features:")
print(selected_features)
# Check the size of the new feature set
print("Size of New Feature Set:", X_new.shape)
# ------------------------------------- Wrapper Method -----------------------------------------------------
# Separate the features (X) and target variable (y)
y = df['target_variable']
X = df.drop('target_variable', axis=1)
# Initialize the Random Forest classifier
clf = RandomForestClassifier()
# Initialize RFE with the classifier and number of desired features to select
n_features = 200 # Number of top features to select
rfe = RFE(estimator=clf, n_features_to_select=n_features)
# Fit RFE to the data and transform the features
X_new = rfe.fit_transform(X, y)
# Get the selected feature indices
feature_indices = rfe.get_support(indices=True)
# Print the selected feature indices
print("Selected Feature Indices:")
print(feature_indices)
# Check the size of the new feature set
print("Size of New Feature Set:", X_new.shape)
# ------------------------------------- Embedded Method -----------------------------------------------------
# Separate the features (X) and target variable (y)
y = df['target_variable']
X = df.drop('target_variable', axis=1)
# Initialize the RandomForestClassifier model
rf_model = RandomForestClassifier(random_state=45)
# Fit the RandomForestClassifier model to the data
rf_model.fit(X, y)
# Get feature importances from the trained model
feature_importances = rf_model.feature_importances_
# Sort the feature importances in descending order
sorted_indices = feature_importances.argsort()[::-1]
# Set the number of top features to select
k = 5
# Get the indices of the top k features
selected_feature_indices = sorted_indices[:k]
# Get the selected feature names
selected_features = X.columns[selected_feature_indices]
# Print the selected feature names
print("Selected Features:")
print(selected_features)
# Create a new DataFrame with the selected features
X_new = X[selected_features]
# Check the size of the new feature set
print("Size of New Feature Set:", X_new.shape)
Results & Discussion
– – – –

Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
Conclusion & Future Work
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
Additional Documents
Original Dataset: Github Link.
Guide: Vipin Shukla